OuteTTS
综合介绍
OuteTTS 是一个开源的文本转语音(TTS)项目,它利用纯语言模型的方法来生成语音,而无需对现有的大型语言模型(LLM)架构进行修改。 这种设计确保了它能与多种库和工具高度兼容,让开发者可以轻松地为各种应用集成语音功能。 OuteTTS 的核心特点是它能够通过简化的流程,直接利用大型语言模型生成高质量的音频。 它支持零样本语音克隆功能,只需几秒钟的参考音频,就能模仿新声音的韵律、情感和口音。 该项目提供了多个版本的模型,支持包括英语、中文、日语、韩语在内的多种语言,并兼容 llama.cpp 等多种后端,适合在不同硬件上运行。
功能列表
- 纯语言模型驱动:无需复杂的适配器或多阶段处理,直接通过大型语言模型(LLM)将文本转换为语音,简化了工作流程。
- 语音克隆:支持零样本(Zero-shot)语音克隆,能够根据仅几秒钟的参考音频,复制特定说话人的声音特质,包括情感和口音。
- 多语言支持:支持英语、中文、日语、韩语、法语和德语等多种语言的语音合成。
- 高质量语音输出:经过在海量、多样化数据集上的训练,模型能够生成自然流畅的语音。
- 多后端兼容:支持多种推理后端,如 Hugging Face Transformers、llama.cpp、ExLlamaV2 等,以适应不同的硬件和应用环境。
- 说话人配置管理:允许用户创建、保存和重复使用自定义的说话人配置文件,提高了语音克隆的效率。
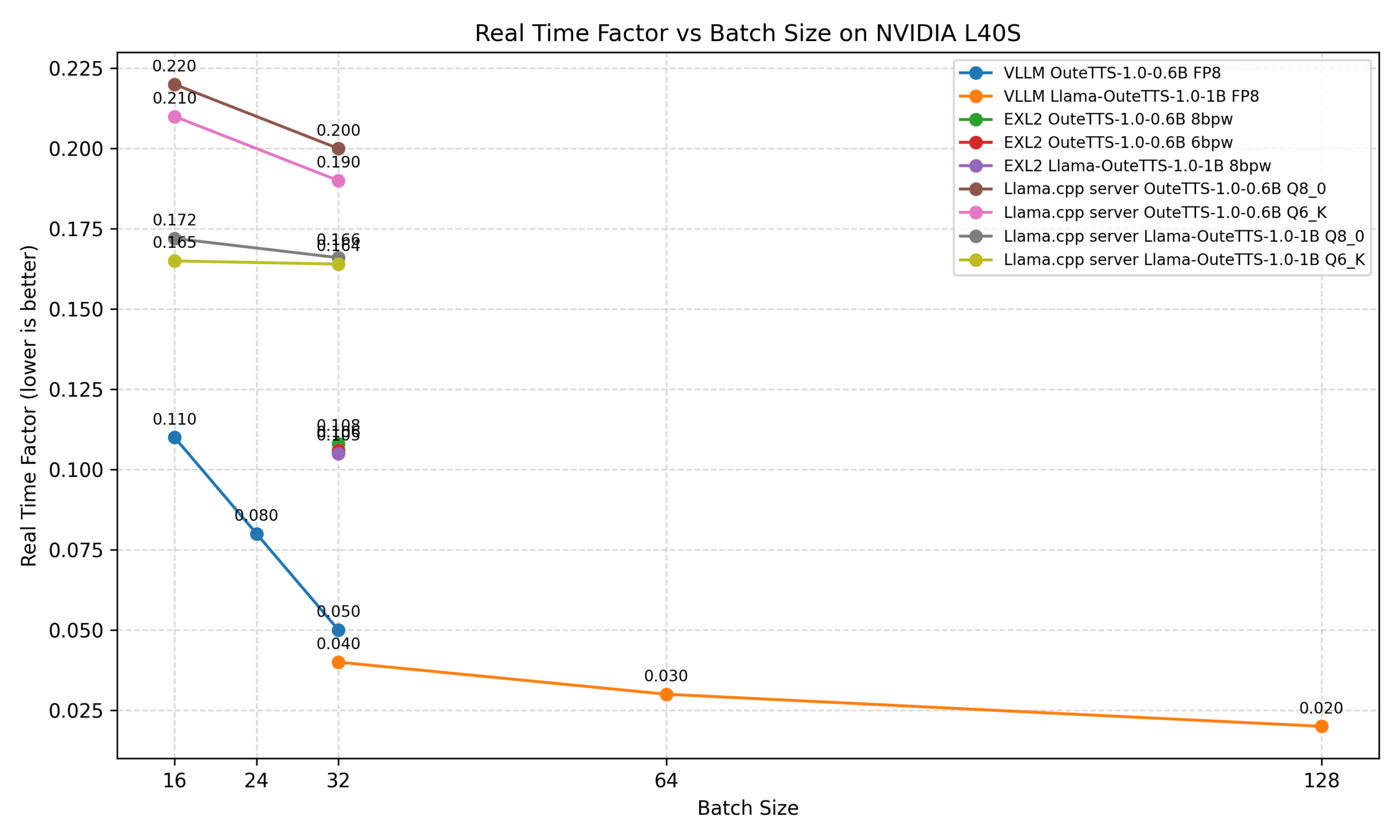
- 批处理推理:支持高吞吐量的异步批处理推理,适用于需要大规模生成语音的场景。
使用帮助
OuteTTS 提供了一个相对简单的 Python 接口,让用户可以快速上手。以下是详细的安装和使用流程。
第一步:环境准备与安装
在开始之前,你需要一个正常的 Python 环境。官方推荐使用 Python 3.11 版本。 同时,由于 OuteTTS 默认安装 llama.cpp 的 Python 绑定,你可能需要根据你的硬件(CPU 或 NVIDIA GPU)来配置编译环境。
- 安装 C++ 编译工具:在 Windows 系统上,你需要安装 Visual Studio 并选择 “使用 C++ 的桌面开发” 工作负载。 在 Linux 或 macOS 上,通常需要安装
build-essential或Xcode command-line tools。 - 创建虚拟环境 (推荐):为了避免与其他项目产生依赖冲突,建议创建一个独立的 Python 虚拟环境。
python -m venv outetts_env source outetts_env/bin/activate # 在 Linux 或 macOS 上 outetts_env\Scripts\activate.bat # 在 Windows 上 - 安装 OuteTTS:OuteTTS 的安装非常直接,使用
pip即可完成。如果你有 NVIDIA GPU 并希望获得加速效果,需要确保已安装对应的 CUDA 工具包。pip install outetts安装过程会自动处理大部分依赖项,包括
llama.cpp-python。
第二步:生成第一个语音
安装完成后,你可以通过一个简单的 Python 脚本来生成语音。OuteTTS 的接口设计得非常直观。
- 编写 Python 脚本:创建一个名为
test_tts.py的文件,并输入以下代码:import outetts import sounddevice as sd import numpy as np # 1. 初始化接口 # auto_config 会自动下载并配置推荐的模型 # 默认使用 llama.cpp 后端,适合在 CPU 上高效运行 interface = outetts.Interface( config=outetts.ModelConfig.auto_config( model=outetts.Models.VERSION_1_0_SIZE_1B, backend=outetts.Backend.LLAMACPP, quantization=outetts.LlamaCppQuantization.FP16 ) ) # 2. 加载一个默认的说话人 # 你可以使用 interface.print_default_speakers() 查看所有可用的默认说话人 speaker = interface.load_default_speaker("EN-FEMALE-1-NEUTRAL") # 3. 配置生成参数 generation_config = outetts.GenerationConfig( text="Hello world, this is a test from OuteTTS.", speaker=speaker, sampler_config=outetts.SamplerConfig( temperature=0.4 # 温度参数影响输出的随机性 ) ) # 4. 生成语音 output = interface.generate(config=generation_config) # 5. 保存到文件 output.save("output.wav") # (可选) 直接播放语音 # sd.play(np.frombuffer(output.wav_bytes, dtype=np.int16), samplerate=24000) # sd.wait() print("语音已成功生成并保存为 output.wav") - 运行脚本:在终端中运行该脚本,程序会自动下载所需的模型文件(首次运行时需要等待),然后生成名为
output.wav的音频文件。python test_tts.py
第三步:使用语音克隆功能
OuteTTS 强大的地方在于它的语音克隆能力。你只需提供一个几秒钟的音频样本,就能让模型模仿这个声音说话。
- 准备参考音频:录制或准备一个清晰、无背景噪音的
.wav格式音频文件,时长建议在 10 秒左右。 将其命名为my_voice.wav并放在项目文件夹中。 - 修改脚本以克隆语音:修改之前的
test_tts.py文件,使用create_speaker方法来创建你自己的说话人配置。import outetts # 1. 初始化接口 (同上) interface = outetts.Interface( config=outetts.ModelConfig.auto_config( model=outetts.Models.VERSION_1_0_SIZE_1B, backend=outetts.Backend.LLAMACPP, quantization=outetts.LlamaCppQuantization.FP16 ) ) # 2. 从你的音频文件创建说话人 # 这一步会分析音频并提取声音特征 my_speaker = interface.create_speaker("my_voice.wav") # (可选) 保存这个说话人配置,以便将来直接加载使用,无需再次创建 interface.save_speaker(my_speaker, "my_speaker.json") # 3. 使用克隆的说话人生成语音 generation_config = outetts.GenerationConfig( text="This is my cloned voice. I can say anything you want.", speaker=my_speaker, sampler_config=outetts.SamplerConfig( temperature=0.4, repetition_penalty=1.05 # 可以调整重复惩罚参数以优化效果 ) ) # 4. 生成语音并保存 output = interface.generate(config=generation_config) output.save("cloned_output.wav") print("克隆语音已成功生成并保存为 cloned_output.wav")
处理长文本
对于较长的文本,OuteTTS 提供了分块生成(Chunked Generation)的模式,可以自动将长文本分割、处理并无缝拼接成一个完整的音频文件,避免了质量下降或内存问题。只需在 GenerationConfig 中将 generation_type 设置为 outetts.GenerationType.CHUNKED 即可。
generation_config = outetts.GenerationConfig(
text="A very long text that goes on and on...",
speaker=my_speaker,
generation_type=outetts.GenerationType.CHUNKED, # 使用分块模式
sampler_config=outetts.SamplerConfig(temperature=0.4)
)
通过以上步骤,你就可以轻松地在本地计算机上使用 OuteTTS 的文本转语音和语音克隆功能了。
应用场景
- 内容创作视频制作者和播客主播可以利用 OuteTTS 为其内容快速生成画外音或配音,甚至可以克隆自己的声音来自动化一部分录制工作。
- 有声读物制作将电子书或长篇文章转换为有声读物,让用户可以在通勤或休息时收听,提升了内容的可访问性。
- 开发语音助手开发者可以集成 OuteTTS 为其开发的智能助手或应用程序提供自然流畅的语音输出,提升用户交互体验。
- 辅助功能工具为视力障碍用户开发屏幕朗读器或文本阅读工具,将网页、文档等书面内容转换为语音,帮助他们获取信息。
- 自动化新闻播报新闻机构可以使用该工具将新闻稿件自动转换为广播级质量的语音,用于新闻播报或音频资讯服务。
QA
- OuteTTS 是什么?OuteTTS 是一个开源的文本转语音(TTS)引擎,它基于大型语言模型构建,能够生成自然的语音,并支持语音克隆功能。
- 这个项目是免费的吗?是的,OuteTTS 是一个开源项目。根据其在 Hugging Face 上的信息,不同的模型版本遵循不同的开源许可协议,例如 CC BY-SA 4.0 或 CC-BY-NC-SA-4.0,使用前请注意具体模型的许可证。
- 我需要什么样的硬件来运行 OuteTTS?OuteTTS 可以在普通的 CPU 上运行,因为它支持
llama.cpp后端。如果拥有 NVIDIA GPU,也可以配置使用 CUDA 进行加速,以获得更快的推理速度。 - 语音克隆的效果好吗?是的,OuteTTS 的语音克隆功能可以很好地捕捉参考音频的音色、情感和口音。 为了达到最佳效果,建议使用清晰、无噪音、长度在10秒左右的参考音频。
- OuteTTS 支持哪些语言?较新的模型版本(如 v0.3)已支持英语(en)、日语(jp)、韩语(ko)、中文(zh)、法语(fr)和德语(de)。